
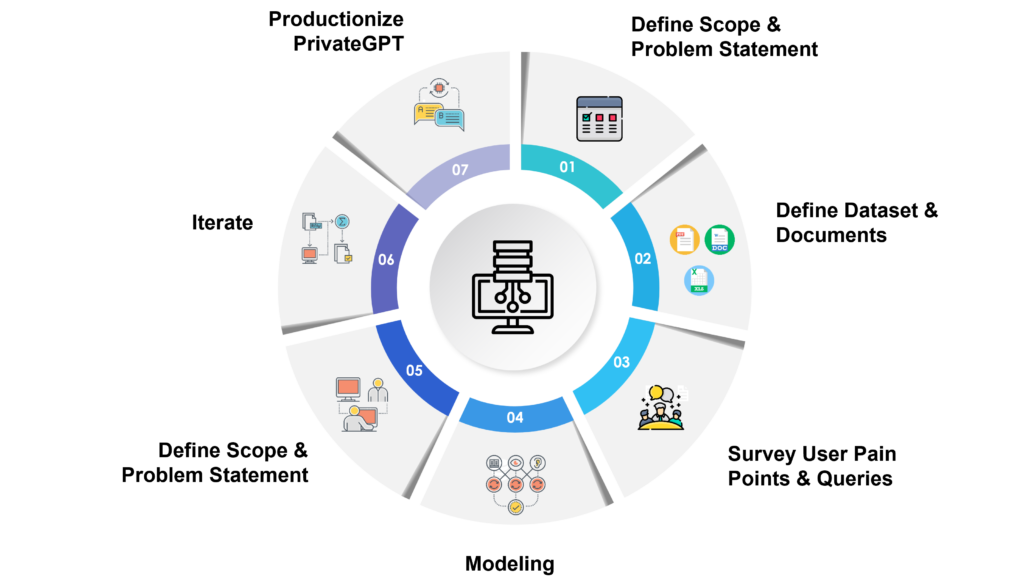
Our Seven Step Process to Customize ChatGPT
Local ChatGPT Architecture

1. Define Scope & Problem Statement
- What does successful Secure ChatGPT look like?
- How will we measure success? Increased productivity? Reduced cost? Increased sales?
- Develop a mutual project plan
- Identify a mutual resource plan
2. Define Dataset & Documents
- What documents are used for today’s business process?
- How frequently are those documents updated?
- Who needs access to those documents?
- Where are those documents stored?
- What is the most critical information in the documents?
- Any PIA or HIPPA information?
3. Survey User Pain Points & Queries
- What information is frequently needed?
- How long does it take to find information?
- What are some of the nuances of documents?
- How are documents generated?
- What information can be wrong in the document?
4. Modeling
- Building the PrivateGPT
- Ingesting the data
- Prompt Engineering tuning
- Knowledge-based tuning
- Initial results accuracy & tone
- Identify cases of hallucinations
- Establish basic guardrails
5. Piloting with Limited Users
- Pilot the PrivateGPT with limited users
- Gather user feedback
- Identify false responses
6. Iterate
- Further, tune the model parameters to increase accuracy
- Reduce/eliminate hallucination
- Ingest additional documents
- Establish new accuracy
7. Productionize PrivateGPT
- Release the production version
- Gather user feedback
- Identify false responses
- Monitor accuracy levels
- Establish on-going support activities